Rethinking How Software Gets Built
Software engineering (SWE) has been one of the most important jobs in the last few decades. Since a great deal of our economy is running on software, being able to create software that powers those industries is something that we as humans have put a lot of our attention into. And we did well! The progress is more than visible.
Now, there are many models for doing software engineering at the team level, from waterfall to agile and others. All of them have pros and cons, and it has been written about them in a great deal, so I won’t be talking about them here.
What I will talk about is a new model that is emerging, one that addresses how you do software engineering at the task/problem level. No matter what team-level approach we take, in the end it always boils down to how an individual is actually doing their own task to solve a specific problem.
My goal here is to show you the workflow I have seen works in practice, in a way that dramatically speeds up the delivery of software solutions, and which I think is here to stay.
SWE workflow so far
In the software engineering workflow, we have three phases:
- Planning - where we discuss what needs to be done
- Execution - where a person sits down and does what was planned
- Verification - where someone else checks the quality of what was executed
When thinking about all three phases, in theory, we think of them as equally important, right? Without a good plan you cannot execute correctly, without good execution you don’t get a good outcome, and without verification the execution can slip. So in our minds they look like this.
- Planning → important
- Execution → important
- Verification → important
Note: Those phases are a simplification of what the real process looks like. For example, here I assume that simple self-verification is the part of the execution process: you check your work, find the error, fix it, and then continue with the execution.
But in practice, this is often not the case. The “real” workflow looks more like this:
- Planning → yes, but not in full detail
- Execution → full focus
- Verification → skipped when needed

The Reality of Planning
All of us plan out how we want to execute a specific task, but very rarely do we sit down to write a plan for it. Understandably so. It would take too much time if we wrote a plan for every single task. But this type of not-writing-anything-down approach is also often used even when dealing with complex tasks with wide scope. We do think about the plan of course, but most of the time we still keep it in our heads and go straight to execution.
The main problem with it is that during the execution we see the details of what we did not think about while planning in our head, and then we need to change a lot of code that we already wrote. This isn’t necessarily bad, and sometimes the only way to figure out the details is to start working on the solution, but at the same time, there are a lot of cases where a good plan would have helped us enormously, and our execution would have been more efficient.
There are also instances where you simply inherit the “plan” (scope/proposal) for your task, that someone else prepared. The problem here is even more evident. When we are not planning for ourselves, we inherently assume things that the other person doesn’t, which then lowers execution efficiency down the line.
Execution and 10x Engineers
Execution is hard. It is not only about writing code. In SWE, it is also about everything else when the code is already written. One of the clearest ways this shows up in practice is in how teams rely on the rare people who are exceptionally good at executing tasks.
If you’ve been working in a software organization, you know about those one or two colleagues who are exceptional engineers. Everyone in the organization knows that whatever task you give them, they will do it perfectly. There are different names for this type of engineers. Some call them 10x engineers, some staff engineers. Some even call them magicians. But no matter the name, the point is that they’re really really good at solving things.
If you’ve been around them in a team or organization, then you also know this unspoken rule and premise that if you give those engineers a task, you don’t have to explain it much, you just give it to them and they will adapt, even if the planning is not fully clear.
It is all based on the premise that the execution part will be perfect.
The whole focus gets put on the execution part of the process. 10x engineers do it perfectly (that’s why they have this “10x” prefix after all), but not all engineers are 10x engineers. For the majority of individuals doing software work, execution is rarely perfect, especially if they do not have much experience in the field.
For this reason, there needs to be a strict verification process.
Verification Under Pressure
Now, for the verification part, we (as humans working on software), are not too sloppy about it. A great deal of practices has been established and applied to make sure that the software being written is actually verified to be correct. And it works. At least most of the time.
But there are some instances where the verification part gets less attention, and that is often when the person doing the execution part of the process is really experienced. We know they are really good, which is why we trust that they do not need to get checked or verified. And that the execution will still turn out as we expect.
Also, one of the most common situations where verification slips is when the timeline is tight, meaning that a software engineer has a really short deadline to deliver the software, or when team capacity is not high enough for someone to spend time tracking every single thing the software engineer wrote. In these cases we still do verification, but the verification process itself is of lower quality.
Why is it like this
The interesting question we can ask ourselves is: why do we operate like this? Why don’t we have equally good planning, execution, and verification? It is not like companies, or teams, or even individuals, want this. No one wants to have suboptimal results and bad outcomes, get fired, or miss the quarterly target. So what is it then?
The answer is simple: we have limited resources. Those limited resources are usually time and people. As in the verification example above, the deadlines we are pushing for constrain our time to spend equal effort on all three parts of the SWE process, to make them perfect. Also, there are not enough 10x engineers out there. You cannot easily find them. When you find them, you are probably not the first and only one, which means other people are looking for them, which means they are in high demand. We also don’t have a factory for 10x engineers. If someone has a potential to become one, it takes at least years in order to be able to reach that level.
So the bottlenecks to delivering high-quality software are real.
Is there anything we can do to overcome them?
The New Workflow
Recently, over the last one to two years, we got the opportunity to try out a new workflow model. This model is slowly (or maybe not so slowly) taking over the SWE industry in terms of the individual approach of working on software engineering tasks. Many are adopting it, without even being aware that they are operating in a model that we just did not have before.
Why do we have a new workflow model now?
Well, a big part is that AI is now able to write code.
It is also able to write more and more code with higher and higher quality across different software domains. There are also benchmarks that measure how long an AI agent can run autonomously to solve tasks of human-equivalent time.
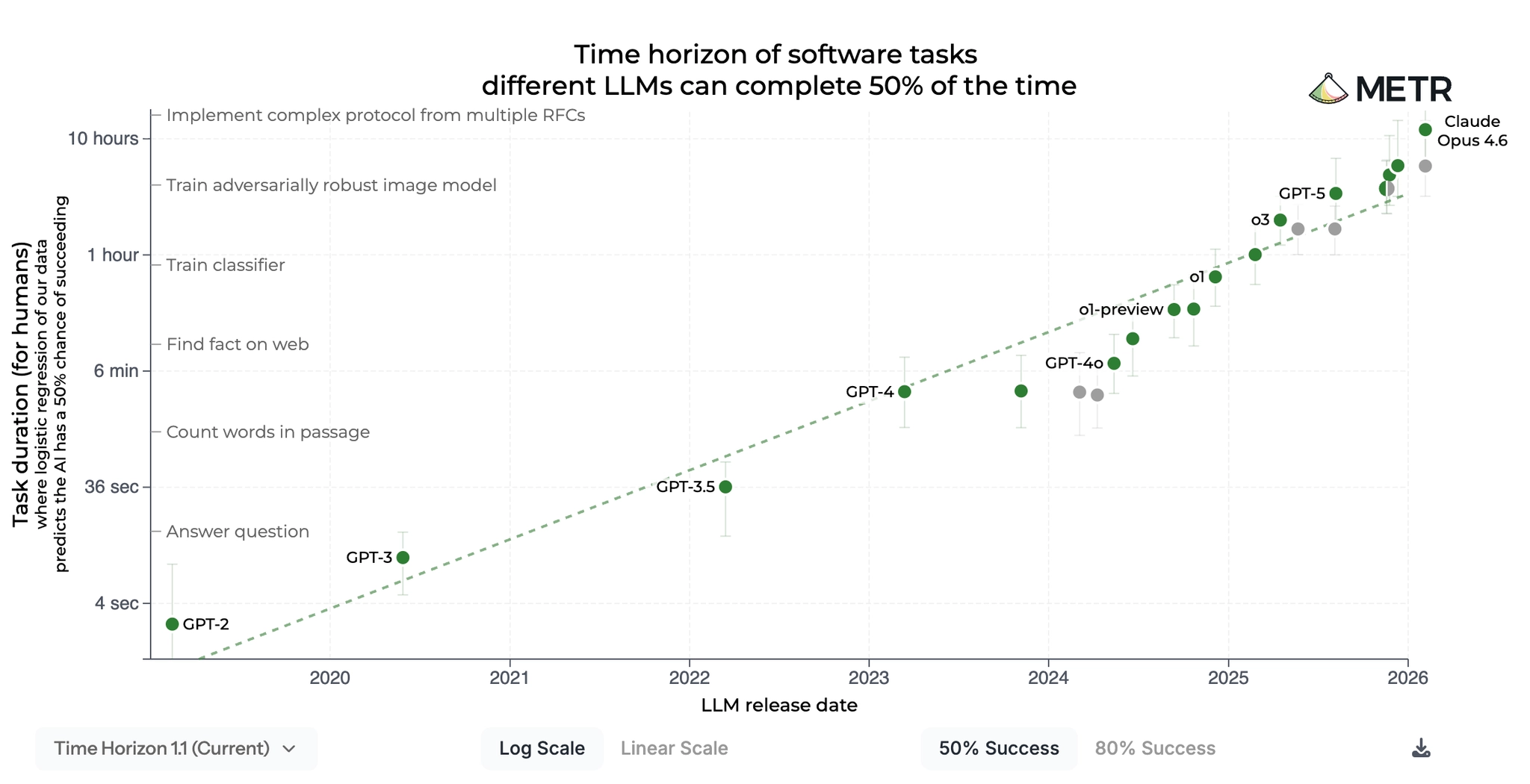
Right now we are somewhere around a few hours max, but the chart is clearly exponential, which means that we jumped from tasks measured in minutes a few months ago, to tasks measured in hours. It would not be surprising if soon enough we start talking about measuring the work of AI agents in days, but let’s see.
So AI now writes good enough code for some specific domain and can run autonomously for minutes or even hours. If you are a software engineer, and you hear that there is now a tool that can write code for you if you explain it well, of course you are going to try it. Not only are you going to try it, but you are probably going to push it to the extreme and throw everything you can at it, just to test it out and see where the limits are.
Why? Well because the process of writing code is (in most cases and for most people) not the main source of fun. There are, of course, examples where you want to sit down, write a piece of code, optimize it, and in that process learn a ton, but the reality is that most of the engineers do not look at writing code like it. They just want to get their job done or to solve problems. So far, the only way to do that was to write the code themselves, but now, when something else can do it for them, they are all for it!
And because of that, we now find ourselves in situations like this:
- Human: Hey AI, please do X
- AI: Sure, here is code that does X
- Human: Thanks AI. You missed Y, please fix it
Early on, it was not rare to find a lot of Y problems for the task X you gave to AI, but recently those have become more rare.
The new model → What is different now
You will notice that the three steps in the conversations above map exactly to the three phases of SWE that we outlined in the beginning. A person creates a plan and gives it to AI. AI then executes it. The person then verifies it. The phases didn’t change. What changed is where we put our attention.
Planning now
It is not rare to hear engineers complain: “Naah, AI doesn’t work. I gave it this task X, and it couldn’t do it at all”. But then you take a look at what the person actually gave to AI as a prompt (plan), and it is usually something along the lines of “Solve my problem, make no mistakes.” Prompts like that may work for a generic solution, but for any complex or specific task with a lot of nuances, it is far from enough. AI can’t simply just “get” what you meant without you providing the proper context and outlining you intentions in detail.
On the other hand, those who do specify the plan in detail are often in shock. Not only does AI execute what you expected, but it also finds the small gaps in your plans that you didn’t think about at all, before you gave it to AI. With clear requirements that cover all the details, the execution part becomes easy. AI is already on a level where it can execute clear instructions almost perfectly.
Many software engineers report that they don’t even write code anymore. The majority of their time goes into writing extremely detailed plans.
Good planning will get you far. Sloppy planning and scoping will produce bad outcomes even if you use tools with the perfect execution.
Execution now
AI writes a lot of code. It started as simple autocomplete, and it could write docs and simple tests. But then it jumped pretty fast to writing whole files, multiple project modules, or sometimes the whole projects. One of the reasons is that the intelligence of the models (LLMs) has increased. The other important one is that models got better at using tools, and we wrote a bunch of tools for them that they can use to achieve better results.
You will hear more and more stories from software engineers that AI did for them something that would have taken them hours or days to code, and when they checked it, it was almost as good as if they had written it themselves. All it took was a good plan and proper context. If you add to that the fact that we now have agent ↔ subagents systems, that means we can spawn multiple instances of “AI” that work on our behalf. The limiting factor then shifts to being able to orchestrate those agents, “manage” the fleet of semi-autonomous systems, and understand the pros and cons of how they work. But more about that in some other post.
Now, the execution is far from perfect all the time. AI makes mistakes. The good thing is that it doesn’t have to be perfect in order for us to benefit from it. If AI does 80%, 90% or more of your plan, you as a person (with your superior human-level judgment) can add the remaining part, and you have probably just saved a lot of time.
My point here is not that execution is solved. My point is that it is becoming cheaper, more abundant, and more parallelizable. The scarce resource in software is shifting from raw code production towards problem framing, providing context, judgment, and acceptance criteria.
Verification now
We often think of AI as another human, and then we try to assess its seniority, but more useful comparison in my opinion is Karpathy’s framing of AI being more like a ghost. It reasons differently from us, which is why we need to check the outputs of its execution.
This means that the verification part is now mandatory. Good plan will get you really far, and the AI execution can produce most of the final solution, but the verification step cannot be skipped, at least not yet. The verification part is not only there for engineers to find bugs in the code AI wrote, but more importantly to understand the code that AI produced so that they can react to it if needed in the future. Until we have perfect and independent code-writing AI agents, there is still a need for verification, which becomes much more important because remember - we are not verifying human output but the output of the “AI spirit”.
Why would we adopt this
The question that would be natural to ask now is: Why would we adopt this model? Why is it superior?
Aside from the previously mentioned fact that a lot of people who code actually do not like to write code, there is an additional argument, which is that this model scales better!
I will demonstrate:
If I ask you to calculate the square root of 1789, you probably won’t be able to do that in a second or two. But then, if I ask you if the answer is 50, you can easily and confidently say that it is not. And if I ask you why you are so confident, you would probably tell me that you quickly did 50×50 in your head, and you know this is not the original number I asked you to calculate the square root of.
What you did here is that you verified that the potential answer I suggested is not correct instead of performing the whole execution of running the square root algorithm in your head.
This is Asymmetric Verification. The point of it is that verification is often easier, cheaper, or faster than the execution of the same process.
Remember the 10x engineers from above and how we don’t have a factory of them? Well, that is also not that big of a problem anymore, because in this case the 10x engineer becomes the Planner and Verifier, who now provides the detailed instructions and oversees the execution. Instead of 10x-ing the execution of one problem, they plan and verify the execution of 2, 3, or more problems.
This is why the new model scales better: strong engineers can now plan and verify more executions than they could personally produce alone.
One interesting thing about this new model is that we still have the problem of limited resources, but those are no longer time, or knowledge, or people. They are now AI tokens. Which means money. And teams and organizations can usually scale money faster and more efficiently than they can scale people and time. You can see this in multiple real-world examples where companies like Shopify give their employees all AI tools needed to execute their tasks. Those tools probably cost a lot of money, but it seems that they are worth the output.
New Model - Summary
Looking at it from the same three phases that we discussed in the beginning, the summary of this new model of doing software engineering now looks something like this:
- Planning → crucial
- Execution → cheaper, more abundant
- Verification → mandatory
AI cannot just “get” what you meant. You need to explain it well, or at least provide the right context. If you don’t, the quality of the result is uncertain. Planning becomes crucial.
Instead of being the bottleneck, execution is now scalable, which means that with good planning we can get a huge part of the execution done correctly by something else, and then verify it fast. Engineers can still write code themselves, and in specific context this is what must happen, but now, for the first time, it is not the only choice. Additionally, the capabilities of AI in the field of writing code don’t seem to slow down.
But AI is not perfect, and we as humans still want to be in control and understand what code AI wrote, so verification step is mandatory. Luckily, verification is often easier, cheaper and faster than execution, which is why it makes sense to put a lot of attention to it.
Actually, nothing new
When you zoom out, this model is not new. We have already been running this model for a long time in software engineering workflow, way before AI was relevant. How? Well, instead of AI, we used different seniority levels of engineers.
In the team or organization, you have senior engineers who have years or decades of experience and write really good code. But you also want to hire talented juniors, who can gain the experience and later take on senior roles.
In most projects, your team consists of both. Senior engineers plan the tasks for the team, and then they delegate them to their more junior colleagues, who execute the task in the best way they can, and then get back to their superiors, who verify their work.
Sounds familiar? Those are the same three phases we have been talking about so far, and this type of relationship has been in the IT industry for decades.
With this exact model, we - humans - have become really good at solving problems. Now we got a kind of speed-up because everyone can have their own younger colleague, who maybe doesn’t understand how everything works and does not have the same experience or context as you do, but oh boy it really wants to help you do your tasks.
This is the real shift here - the software engineering loop stays the same, but where we put most of our attention is what is new, exciting, and what creates leverage.
Other industries?
In this post we talked specifically about the SWE industry and how using AI gives us a more efficient model of software creation. But I want to emphasize one point which is that everything we talked about is not related just to writing code. Coding is just the first area where it got adopted (since frontier AI companies focus on it the most (for their own reasons)). The old workflow described above is basically how every “knowledge work” works. Which means that the new model can be directly applied to a lot of domains.
It remains to be seen how and when this workflow will be applied to other fields of our human creativity. We already have early previews of Claude Code being functional in a few non-SWE industries, with examples like it handling Excel sheets and creating presentations. Also, Anthropic itself put out this chart showing the impact of AI on the general labor market.
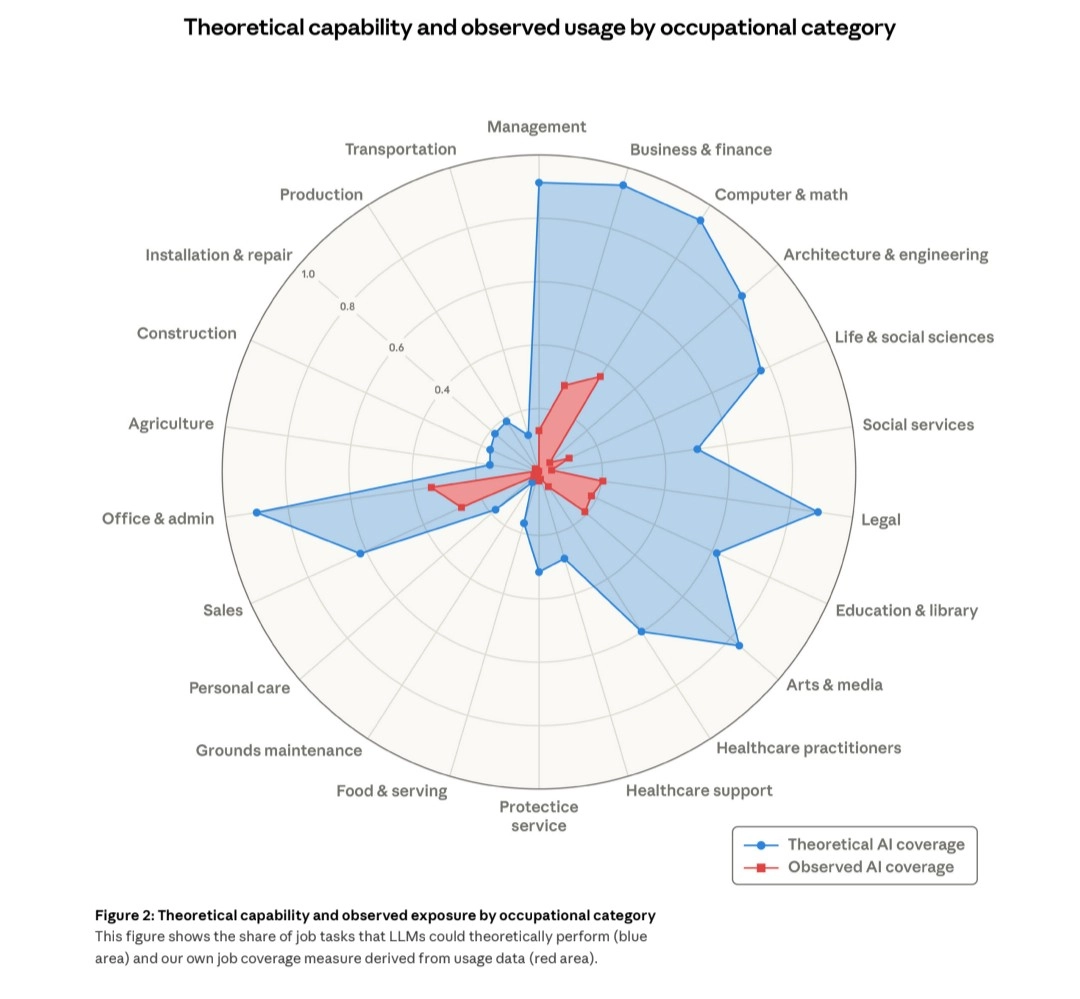
Whoever brings this model successfully into new industries has a huge market to capture over the years to come, and my bet is that we will see much much more of it becoming part of our lives really soon.
Wrapping up
Software engineering has changed, but not in a way that AI took over and people are now jobless. We still run the same old loop of planning, executing, and verifying. What changed is where we put our focus. Execution is no longer the only scarce part, and significant advantages can now be gained by focusing more on planning, context, and verification. This framework is already producing results, and we are only scratching the surface of how far we can scale it. And the best part? It is applicable outside of SWE too!
I have already started applying this model in other parts of my work and life, and I couldn’t be more excited about its potential. I will write more about them in my next posts.
Until then, I will leave you with this: We have clearly entered a new era of work and how we approach it. A lot of old principles are useful, but now there are also many changes and opportunities that come with them. Will you adapt fast enough?
Thanks for reading!